Details
-
 Epic
Epic
-
 Must have
Must have
-
None
-
prepareData Functionality
-
SRCnet
-
-
0
Description
Introduction
Granting users direct access to data from repositories managed by the Data Management System (DDM) would significantly benefit SRCNet. This approach avoids creating local copies for large SKA data products, addressing the following concerns:
- Storage Quotas: Replicas created outside the DDM must be counted into user quotas. Since SKA data cubes can be several terabytes, users might require quotas comparable or exceeding this size across nodes for efficient scientific workflows. This translates to reserving a significant amount of storage space for user areas, potentially 10-100 TBs per user per node, multiplied by the expected user base.
- Lifecycle Management: Replicas outside the DDM lack lifecycle management by SRCNet services. DDM-created replicas could utilise timestamps for deletion after a period of inactivity. Local copies (outside the DDM) are difficult to delete as they might be genuine user data, leading to near-permanent storage usage.
- Redundant Replicas: Local copies can lead to users accessing different replicas of the same data product, even when a replica already exists in hot storage near the computing area. DDM-created replicas could be shared read-only with multiple users.
- Improved Efficiency: Linking to existing data allows immediate access, skipping the "download to user area" step. However, this step might still be necessary for multi-tier storage nodes (explained in Note 3).
Avoiding the creation local copies for large SKA data products, we expect to get the following benefits:
- Cost Implications. These issues can significantly impact node costs. Data copies might be created multiple times for the same file with undefined lifetimes, controlled only by user quotas. When quotas are full, users are forced to clean up their areas. DDM-managed replicas accessible in read-only mode wouldn't contribute to user storage quotas, resulting in more controlled node data management and a system optimized for user analysis and scientific production. While performance improvements might be an immediate benefit, cost reduction remains the primary consideration for SRCNet.
- Performance Considerations. Performance implications exist (e.g., reading local vs. streamed data). Although local data access is generally faster than streaming, this might be less relevant than the abovementioned cost benefits.
- Optimized Cache Storage with DDM Control. DDM control over replicas facilitates an optimized storage system with multiple replicas of popular data near users and lifespans managed by last access timestamps. This process resembles the approach used by Content Delivery Networks (CDNs) (https://en.wikipedia.org/wiki/Content_delivery_network) for efficient website content delivery across time zones.
Additional Notes:
- Downloading data to user areas via streams is already supported by SRCNet services (TAP->DataLink->Download). This feature aims to optimize cost and performance.Downloading data to user areas via streams is already supported by SRCNet services (TAP->DataLink->Download). This feature aims to optimize cost and performance.
- Processes requiring read/write access on the original data necessitate downloading data to user areas. This proposed approach primarily focuses on read-only data access. Although this will be allowed, we discourage adding additional layers onto large datasets, promoting the analysis of data by producing new products with references to the original data product IDs, a process more efficient for SKA data.
- For multi-tier storage systems (e.g., with RSEs using high-latency technologies), it's recommended to have an RSE near the computing area. Data is then moved to this storage during the "prepare data" process. In simpler terms, the staging area is also part of the Rucio DDM. DDM can remove replicas of popular data from the staging area when the data is no longer accessed or move them to a less-performance storage RSE. For instance, using a layer like Cavern/VOSpace, the reference to the symbolic link would be replaced with a reference to a long-term replica into a less efficient RSE (different tier).
EPIC Definition
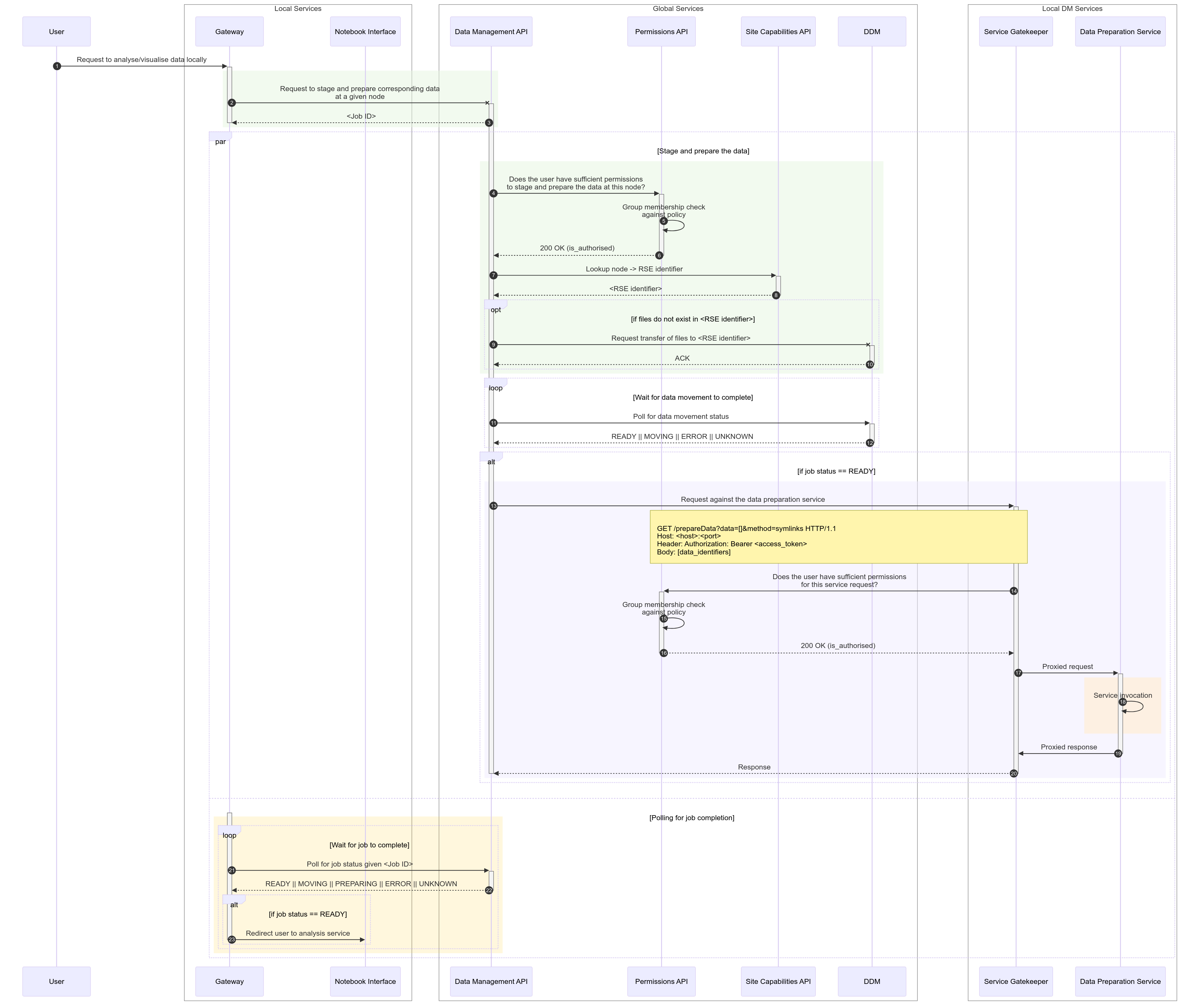
The current EPIC content is a minimal implementation of the prepareData function. The involved steps are:
- Data selection for analysis at the gateway (shopping basket already implemented)
- Gateway invokes a REST service to request data available for the user (already implemented in gateway and DDM) (may require updates)
- DM API checks user access rights for the selected data (partial implementation, additional work needed for a basic prototype)
- DM API (with DDM system) ensures data presence at the local node (if necessary, by invoking replica creation - mostly done)
- DM API invokes the "set data available for the user into user area" method (the core of this EPIC) e.g. by creating a link to the repository
- User can have info of the process completion (using UWS) (already done)
- User can invoke the analysis button to open a notebook interface (where data can be explored) (mostly done, pending a notebook example to make use of the data)
Breakdown for this EPIC
This operation is further divided into at least four features that can be implemented by different teams in coordination:
- Feature 1: Complete access rights checking using a local node check (gatekeeper)
- Feature 2: API definition for this method - a clear definition will allow a replacement with a more efficient method in the future without strong changes into the rest of the DDM code
- Feature 3: Initial implementation using symbolic links to data on nearby RSEs
- Feature 4: Exploring VOSpace approach for flexible symbolic linking outside Cavern repositories